29 Alternate Sequencing
Some users of this book may wish to present material in different orders. In this section, we present a few sections that have been rewritten so they can occur at different points.
29.1 Lambda: Anonymous Functions (with Tables)
This is an adaptation of Lambda: Anonymous Functions to use Tables instead of Lists.
Let’s revisit the program we wrote in Finding Rows for finding all of the months in a table with fewer than 1000 riders:
shuttle = table: month, riders
row: "Jan", 1123
row: "Feb", 1045
row: "Mar", 1087
row: "Apr", 999
end
fun below-1K(r :: Row) -> Boolean:
doc: "determine whether row has fewer than 1000 riders"
r["riders"] < 1000
where:
below-1K(shuttle.row-n(2)) is false
below-1K(shuttle.row-n(3)) is true
end
filter-with(shuttle, below-1K)
This program might feel a bit verbose: do we really need to write a
helper function just to perform something as simple as a
filter-with? Wouldn’t it be easier to just write something like:
filter-with(shuttle, r["riders"] < 1000)Do Now!
What will Pyret produce if you run this expression?
Pyret will produce an unbound identifier error around the use
of r in this expression. What is r? We mean for r
to be the elements from shuttle in turn. Conceptually, that’s
what filter-with does, but we don’t have the mechanics right. When
we call a function, we evaluate the arguments before the body
of the function. Hence, the error regarding r being unbound.
The whole point of the below-1K helper function is to make
r a parameter to a function whose body is only evaluated once
a value for r is available.
To tighten the notation as in the one-line filter-with expression,
then, we have to find a way to tell Pyret to make a temporary function
that will get its inputs once filter-with is running. The following
notation achieves this:
filter-with(shuttle, lam(r): r["riders"] < 1000 end)
We have added lam(r) and end around the expression that
we want to use in the filter-with. The lam(r) says "make a
temporary function that takes r as an input". The end
serves to end the function definition, as when we use
fun. lam is short for lambda, a form of function
definition that exists in many, though not all, languages.
The main difference between our original expression (using the
below-1K helper) and this new one (using lam) can be
seen through the program directory. To explain this, a little detail
about how filter-with is defined under the hood. In part, it looks
like:
fun filter-with(tbl :: Table, keep :: (Row -> Boolean)) -> Table:
if keep(<row-from-table>):
...
else:
...
end
end
Whether we pass below-1K or the lam version to
filter-with, the keep parameter ends up referring to a
function with the same parameter and body. Since the function is only
actually called through the keep name, it doesn’t matter
whether or not a name is associated with it when it is initially
defined.
In practice, we use lam when we have to pass simple (single line)
functions to operations like filter-with (or transform-column,
build-column, etc). Of course, you can continue to write out names for
helper functions as we did with below-1K if that makes more sense to
you.
Exercise
Write the program to add 10 riders to each row in the
shuttletable above, usinglamrather than a named helper-function.
29.2 Cleaning Data Tables (from CSVs)
This is an adaptation of Cleaning Data Tables to use CSV files, via the VSCode integration, instead of Google Sheets, at code.pyret.org.
29.2.1 Loading Data Tables
The first step to working with an outside data source is to load it into your
programming and analysis environment. In Pyret, we do this using the
load-table command, which can load Comma Separate Value formatted data
either directly from websites or via files added to Github repositories.
include csv
url = "https://pdi.run/f25-dcic-events-orig.csv"
event-data =
load-table: name, email, tickcount, discount, delivery
source: csv-table-url(url, default-options)
end-
urlis the identifier of the web address (URL) where the CSV data we want to load exists. -
load-tablesays to create a Pyret table via loading. The sequence of names followingload-tableis used for the column headers in the Pyret version of the table. These do NOT have to match the names used in the first row of the CSV (which is usually a header row). -
sourcetells Pyret where to load the data from. Thecsv-table-urloperation takes the web address (here,url), as well as options (which control, for example, that we expect there to be a header row).
FIXME: This doesn’t error for CSVs. Should we just ignore, or talk about validation in another way? i.e., introduce sanitizers?
When we try to run this code, Pyret complains about the three
in the Num Tickets column: it was expecting a number, but instead
found a string. Pyret expects all columns to hold values of the same
type. When loading a table from file, Pyret bases the type of each
column on the corresponding value in the first row of the table.
This is an example of a data error that we have to fix in the source
file, rather than by using programs within Pyret. Not all
languages will reject programs on loading. Languages embody
philosophies of what programmers should expect from them. Some will
try to make whatever the programmer provided work, while others will
ask the programmer to fix issues upfront. Pyret tends more towards the
latter philsophy, while relaxing it in some places (such as making
types optional). Within the source Google Sheet for this chapter,
there is a separate worksheet/tab named "Data" in which the
three has been replaced with a number. If we use "Data"
instead of "Orig Data" in the above load-spreadsheet
command, the event table loads into Pyret.
Exercise
Why might we have created a separate worksheet with the corrected data, rather than just correct the original sheet?
29.2.2 Dealing with Missing Entries
When we create tables manually in Pyret, we have to provide a value for each cell – there’s no way to "skip" a cell. When we create tables in a spreadsheet program (such as Excel, Google Sheets, or something similar), it is possible to leave cells completely empty. What happens when we load a table with empty cells into Pyret?
NOTE: currently, using same as orig... need to figure out how error handling should work.
event-data =
load-table: name, email, tickcount, discount, delivery
source: csv-table-url("https://pdi.run/f25-dcic-events-orig.csv", default-options)
end
The original data file has a blank in the discount column. If we load
the table and look at how Pyret reads it in, we find something new in that column:

Note that those cells that had discount codes in them now have an
odd-looking notation like some("student"), while the cells that
were empty contain none, but none isn’t a string. What’s
going on?
Pyret supports a special type of data called option. As the name
suggests, option is for data that may or may not be
present. none is the value that stands for "the data are
missing". If a datum are present, it appears wrapped in some.
Do Now!
Look at the
discountvalue for Ernie’s row: it readssome("none"). What does this mean? How is this different fromnone(as in Sam’s row)?
In Pyret, the right way to address this is to indicate how to handle
missing values for each column, so that the data are as you expect
after you read them in. We do this with an additional aspect of
load-table called sanitizers. Here’s how we modify the
code:
include data-source # to get the sanitizers
event-data =
load-table: name, email, tickcount, discount, delivery
source: csv-table-url("https://pdi.run/f25-dcic-events-orig.csv", default-options)
sanitize name using string-sanitizer
sanitize email using string-sanitizer
sanitize tickcount using num-sanitizer
sanitize discount using string-sanitizer
sanitize delivery using string-sanitizer
end
Each of the sanitize lines tells Pyret what to do in the case
of missing data in the respective column. string-sanitizer says
to load missing data as an empty string ("").
Sanitizers also handle simple data conversions. If the
string-sanitizer were applied to a column with a number (like
3), the sanitizer would convert that number to a string (like
"3"). Similarly, applying num-sanitizer to a column
would convert number-strings (like "3") to an actual number
(3).
Using sanitizers, the event-data table reads
in as follows:
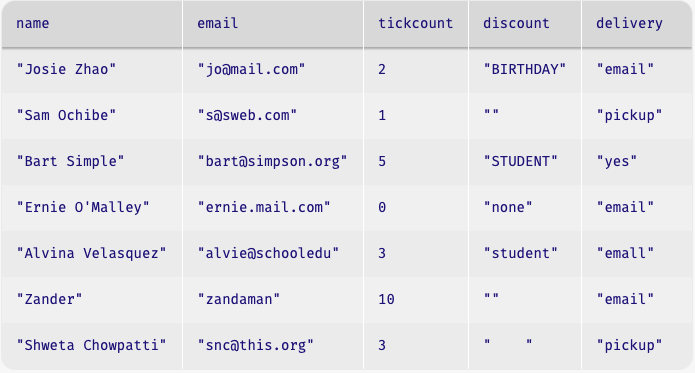
A note on default values:
Unlike string-sanitizer, num-sanitizer does
NOT convert blank cells to a default value (such as 0). There
is no single default value that would make sense for all the ways in
which numbers are used: while 0 would be a plausible default for
missing numbers of tickets, it would not be a meaningful default for a
missing age. It could create outright errors if used as the default
for a missing exam grade (which was later used to compute a course
grade). As a result, num-sanitizer reports an error if the data
(or lack thereof) in a cell cannot be reliably interpreted as a
number. Pyret allows you to write your own custom sanitizers
(e.g., one that would default missing numbers to 0). If you want to do
this, see the Pyret documentation for details.
The lack of meaningful default values is one reason why Pyret doesn’t leverage type annotations on columns to automatically sanitize imported data. Automation takes control away from the programmer; sanitizers provide the programmer with control over default values, as well as the option to use (or not) sanitizers at all.
Rule of thumb: when you load a table, use a sanitizer to guard against errors in case the original sheet is missing data in some cells.